I’m blogging about the development of a new product in Mozilla, look here for my other posts in this series
A while back we got our first contributor to PageShot, who contributed a feature he wanted for Outernet – the ability to use PageShot to create readable and packaged versions of websites for distribution. Outernet is a neat project: they are building satellite capacity to distribute content anywhere in the world. But it’s purely one-way, so any content you send has to be complete. And PageShot tries pretty hard to identify and normalize all that content.
Lately I spent a week with the Activity Stream team, and got to thinking about the development process around recommendations. I’d like to be able to take my entire history and actually get the content, and see what I can learn from that.
And there’s this feature in PageShot to do just that! You can install the add-on and enable the pref to make the browser into a server:
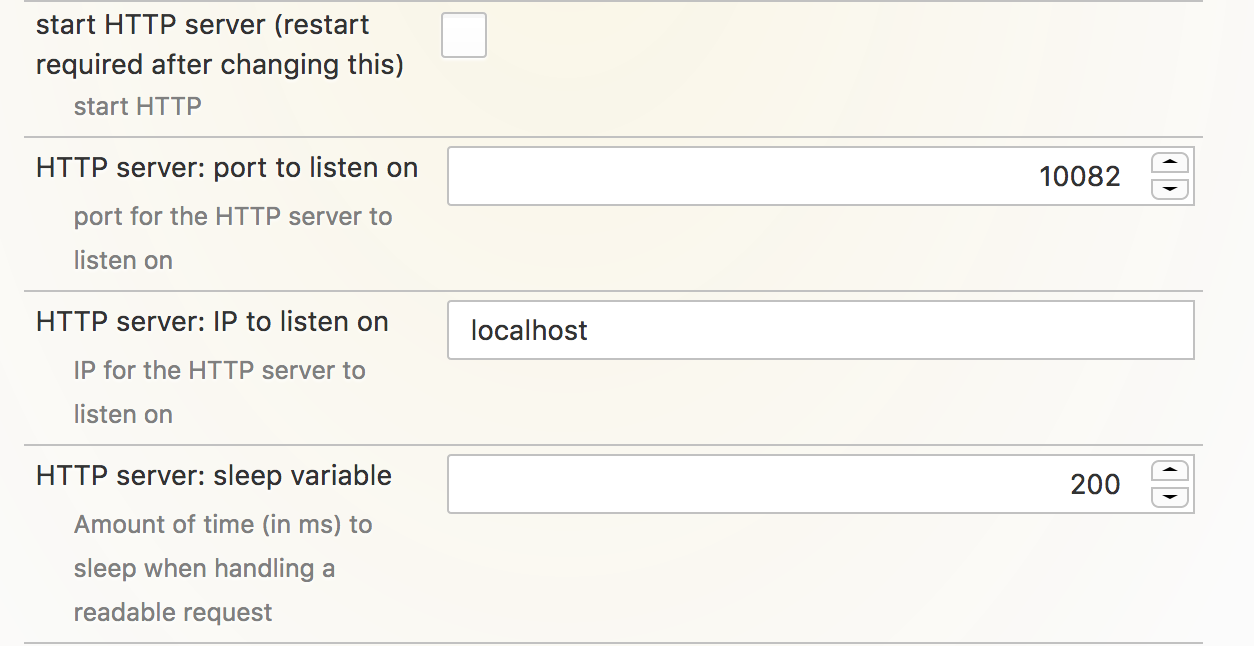
After that you can get the shot data from a page with a simple command:
$ url=https://mail.google.com
$ server=http://localhost:10082
$ curl "${server}/data/?url=${url}&allowUnknownAttributes=true&delayAfterLoad=1000" > data.json
allowUnknownAttributes preserves attributes like data-* attributes that you might find useful in your processing. delayAfterLoad gives the milliseconds to wait, usually for the page to “settle”.
A fun part of this is that because it’s in a regular browser it will automatically pick up your profile and scrape the page as you, and you’ll literally see a new tab open for a second and then close. Install an ad blocker or anything else and its changes will also be applied.
The thing you get back will be a big JSON object:
{
"bodyAttrs": ["name", "value"],
"headAttrs": [], "htmlAttrs": [],
"head": "html string",
"body": "html string",
"resources": {
"uuid": {
"url": "..."
}
}
}
There’s other stuff in there too (e.g., Open Graph properties), but this is what you need to reconstruct the page itself. It has a few nice features:
- The head and body are well formed; they are actually serialized from the DOM, not related to the HTTP response.
- All embedded resources (mostly images) are identified in the
resourcesmapping. The URLs in the page itself are replaced with those UUIDs, so you can put them back with a simple string substitutions, or you can rewrite the links easily. - Actual links (
<a href>) should all be absolute. - It will try to tell you if the page is private (though it’s just a heuristic).
- If you want, it’ll include a screenshot of the full page as a
data:URL (use&thumbnailWidth=pxto choose how wide). - CSS will be inlined in a
<style>tag, perhaps reducing the complexity of the page for you.
Notably scripts and hidden elements will not be included (because PageShot was written to share visible content and not to scrape content).
Anyway, fun to realize the tool can address some hidden and unintentional use cases.